







A Step-by-Step Approach to Grasping the Machine Learning Life Cycle
Powering everything from recommendation systems to self-driving cars, machine learning (ML) has become a cornerstone of contemporary technology. Creating a successful ML model follows a systematic machine learning life cycle to guarantee accuracy, efficiency, and real-world relevance rather than only about programming.
We will outline the seven essential steps of the ML life cycle in this paper, hence clarifying each stage in straightforward language using practical examples. Whether you are a novice or an expert, this book will enable you to grasp how ML projects are created from beginning.
The Machine Learning Life Cycle is a systematic approach guiding the creation, deployment, and upkeep of ML models.
A systematic approach called the machine learning life cycle directs the creation, deployment, and upkeep of ML models. Unlike conventional software, ML models depend on data-driven learning, so success depends on organised processes.
What Makes the ML Life Cycle Important?
Guarantees consistent, scalable models
Lowers mistakes and inefficiencies
Enables good team cooperation
Guarantees models stay current post-deployment
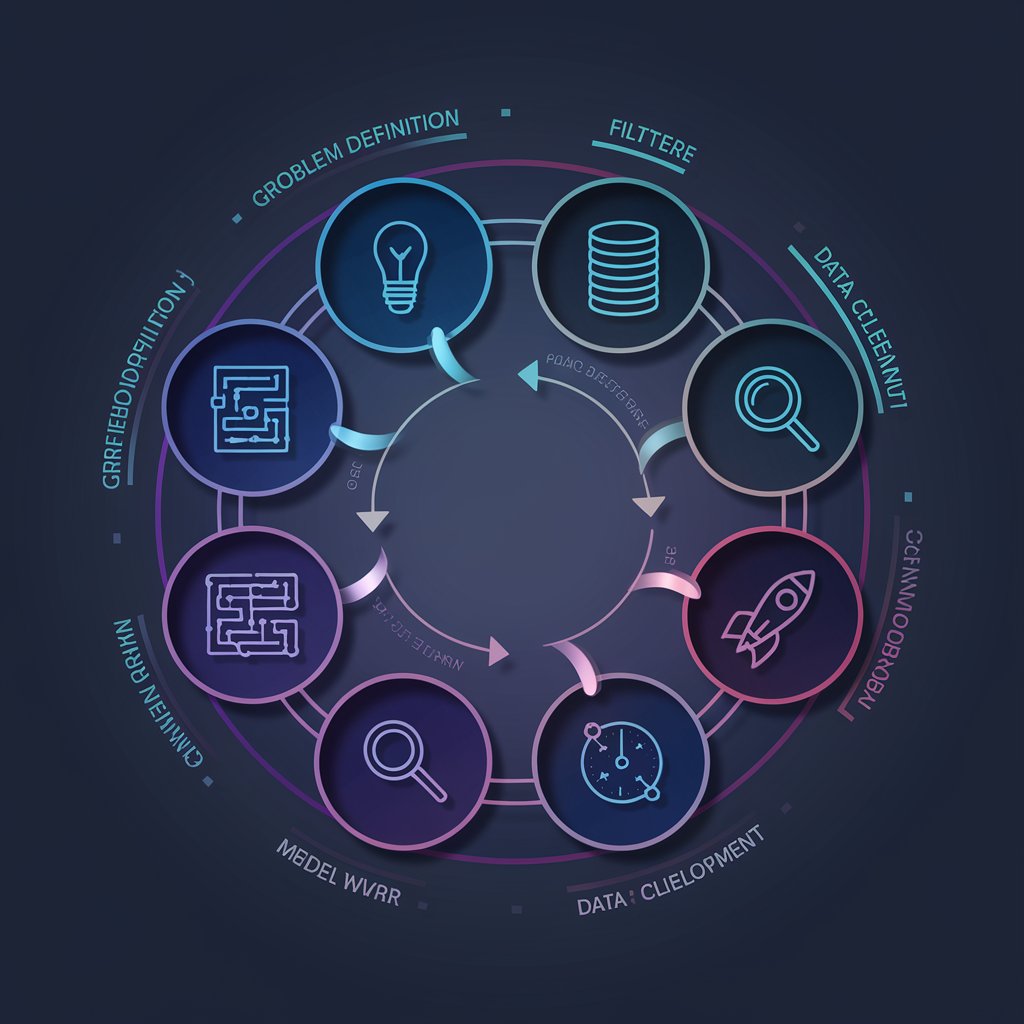
The Seven Stages of the Machine Learning Life Cycle
1.Defining the Problem
Writing one line of code calls for you first:
Determine the business issue—for example, forecasting consumer turnover, spotting fraud.
Establish success criteria: accuracy, precision, recall.
Assess viability (Do you have sufficient data? Is ML the correct answer?
For instance, a bank hopes to forecast loan defaults. Early identification of high-risk candidates helps to lower risk.
2.Gathering Data
ML models require relevant, high-quality data. Among the sources:
Database systems—SQL, NoSQL
APIs—weather data, Twitter
Web scraping (for bespoke datasets)
Datasets open to the public (Kaggle, UCI Repository)
Incomplete, prejudiced, or low-quality data produces inconsistent models.
3.Data Cleaning & Preprocessing
Raw data is untidy. This phase calls for:
Dealing with missing values—removing or imputing data.
Eliminating outliers and duplication.
Scaling/normalizing data—for instance, changing all salaries to the same currency.
Encoding categorical data—for instance, converting "Male/Female" into 0/1.
For instance, a healthcare database with patient records can lack blood pressure readings requiring imputation.
4. Data Analysis in Exploration (EDA)
Before model construction, EDA reveals trends:
Statistical summaries: mean, median, distribution.
Visualisation tools include heatmaps, scatter plots, and histograms.
Finding links between variables, correlation study.
Insight: In an e-commerce database, EDA might show a high correlation between consumer age and buying behaviour.
5. Development of Models
The real ML effort starts now:
Choosing algorithms—neural networks, decision trees, SVM.
Dividing data into testing (20-30%) and training (70-80%) sets.
Training the model using past data.
Assessing performance with measures like as accuracy, F1-score, or RMSE.
For text categorisation, a spam detection system might employ a Naive Bayes classifier.
6. Putting the Model into Use
A model is of no utility if it remains in a Jupyter notebook. Options for deployment are:
Cloud platforms—AWS SageMaker, Google AI Platform.
APIs—Flask, FastAPI for bespoke integrations.
Devices on the edge: IoT or smartphone ML models.
Ensuring the model performs well in real-world conditions—not simply test data—is a challenge.
7. Maintenance & Monitoring
Changing data patterns cause ML models to deteriorate with time. This phase calls for:
Monitoring performance drift (Is accuracy declining?).
Training models with new data.
Correcting prejudices, such an AI recruiting tool favouring one demographic.
For instance, a Netflix recommendation engine has to change with time to reflect changing customer tastes.
Real-World Case:
House Price Prediction
Applying the ML life cycle to a house price prediction model lets us
Predict home costs according on factors including location, size, and amenities.
Collect data from government records, real estate online sites.
Data Cleaning: Fill lacking square foot numbers, delete duplicate entries.
Find in EDA that pricing is more influenced by location than by bedroom count.
Train a Random Forest Regressor on the data.
Include the model into a real estate website's pricing tool under Deployment.
Monitor the model annually as market patterns change.
ML Life Cycle Challenges Answer Bad data quality Invest in validation and data cleaning Model prejudice Employ fairness-aware algorithms Complexity of deployment Deploy MLOps tools—MLflow, Kubeflow. Decline in performance Plan frequent model retraining Final thoughts
Building strong AI systems is a methodical process called the machine learning life cycle. Develop ML solutions that provide genuine business value by following these seven stages—problem formulation, data collecting, preprocessing, EDA, model training, deployment, and monitoring.
Main Points:
ML initiatives call for deliberate planning prior to coding.
Data quality takes precedence over sophisticated algorithms.
Long-term success depends on regular monitoring and updates.
Curious about ML? Follow this life cycle starting with a tiny project—like forecasting customer behaviour or stock trends.
